Today’s blog is written by Marc McDermott, a member of the National Genealogical Society with a deep passion for all things genealogy. Reposted from the Genealogy Explained blog with permission.
There’s been a lot of media coverage lately around cold cases being cracked open using DNA testing and investigative genetic genealogy (IGG).
Cases like the Golden State Killer and those portrayed in ABC’s hit TV show The Genetic Detective leave many people wondering how this process works. This article explains everything you need to know, and addresses some common misconceptions.
The law enforcement process
When a DNA sample is extracted from a crime scene, it can identify a suspect through IGG (sometimes referred to as forensic genealogy).
But before any genetic genealogy takes place, a few things have to happen.
Here’s a high-level overview of how the process works in the United States. Note the process may be different in other countries.
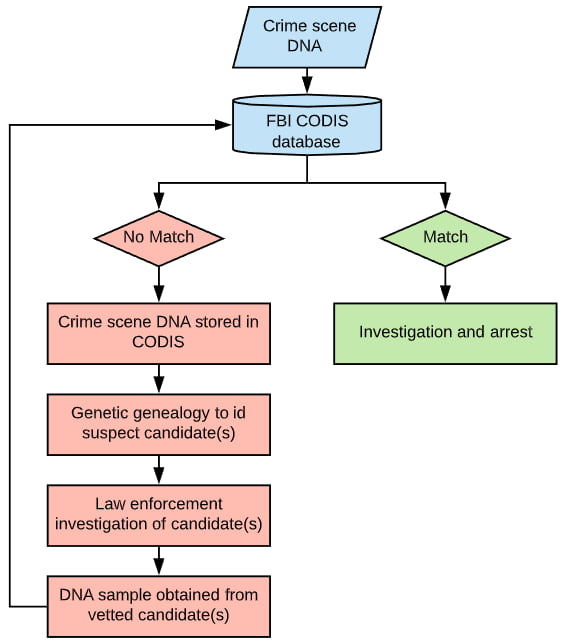
First, the crime scene DNA is uploaded to an FBI database called the Combined DNA Index System (CODIS). CODIS is populated with DNA profiles of both existing criminals (whose crime met the criteria to collect a DNA sample) and crime scene DNA profiles of unknown suspects.
Once uploaded, the system will search the database to match either an existing criminal or additional crime scenes.
If no match is found, the DNA remains stored in the CODIS database for future searches. It’s at this point where investigators may decide to pursue IGG to identify a suspect.
Once a genealogist identifies a potential suspect (or shortlist of possible suspects), law enforcement must lawfully obtain a DNA sample which they compare to the crime scene DNA in CODIS. Only if there is an exact match can an arrest be made.
While there are other technical details I won’t get into, such as STR testing and SNP testing, that’s a basic overview of how the process works.
The genealogy research process
Now let’s talk more about the genetic genealogy component. After all, this is a genealogy blog!
The process sounds complicated, but it’s pretty straightforward.
Here’s a basic overview:
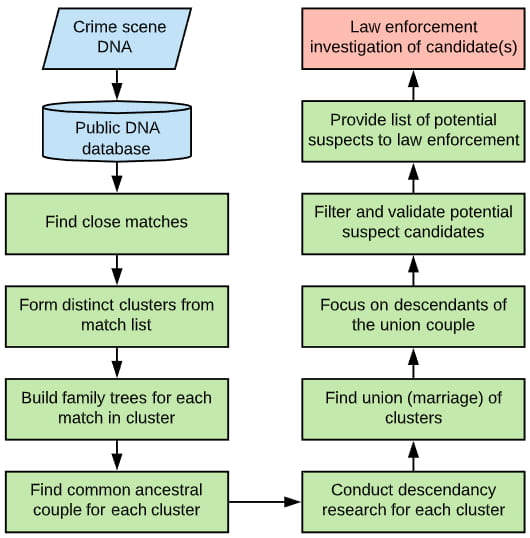
Finding close matches
The DNA profile from the crime scene is uploaded to public databases such as GedMatch. Once uploaded, the DNA “kit” is compared to the entire database, and a list of matches is returned, ordered by the amount of shared DNA.
Note that in Gedmatch the DNA can only be compared to users who have opted in law enforcement’s access.
While not the focus of this article, it’s worth noting that commercial DNA testing companies like AncestryDNA, MyHeritage and 23andMe, do not allow law enforcement to upload DNA. I encourage you to read each company’s policy for the most up to date information on how they deal with law enforcement. I would also recommend a great lecture by Blaine Bettinger that I attended this year at Rootech 2020 in Salt Lake City. The presentation was recorded and uploaded to the Rootstech website.
This is the stage where the genealogist will know almost immediately the scope of the project. If they have several close matches to work with (2nd cousins or closer) and the matches also match each other at a similar level, then the scope is reasonably simple.
If the top matches are beyond, say, third cousin level, the scope will be much more complicated.
That’s because the genealogist has to build out these matches’ family trees to find where they converge. Building out the family trees of two 2nd cousins is far less involved than fourth cousins.
Forming clusters and building trees
Once they have a list of close matches, they see who in that list matches each other (and who does not) to form distinct clusters.
The idea is that every person in a cluster should share a common ancestral couple. So the genealogist works one cluster at a time, working back in time and building out each person’s trees in that cluster to identify the common ancestors for every person in that cluster.
Typically a genealogist would start with the strongest match to get an idea of how many generations back they need to build the tree before moving onto the next cluster and finding a union.
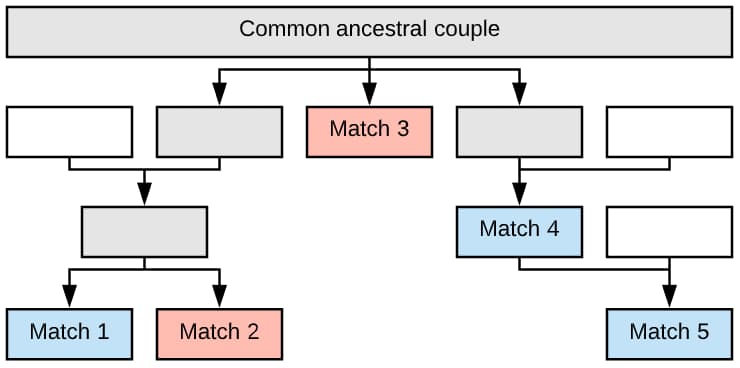
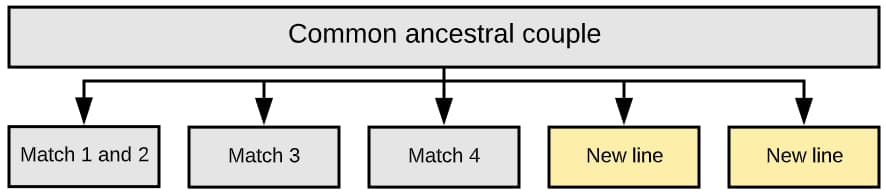
So looking at this basic tree, we know that:
- Match 1 and Match 2 are full siblings (brother and sister)
- Match 3 is the great aunt of Match 1, Match 2, and Match 5
- Match 1 and Match 2 are 2nd cousins with Match 5.
- Match 1 and Match 2 are 1st cousins once removed with Match 4.
- Match 5 is the son of Match 4.
We can take this a step farther and add the shared DNA amounts to each match to ensure the relationships all make sense, given the amount of shared DNA.
Here’s how we can visualize the DNA relationships between the five matches:
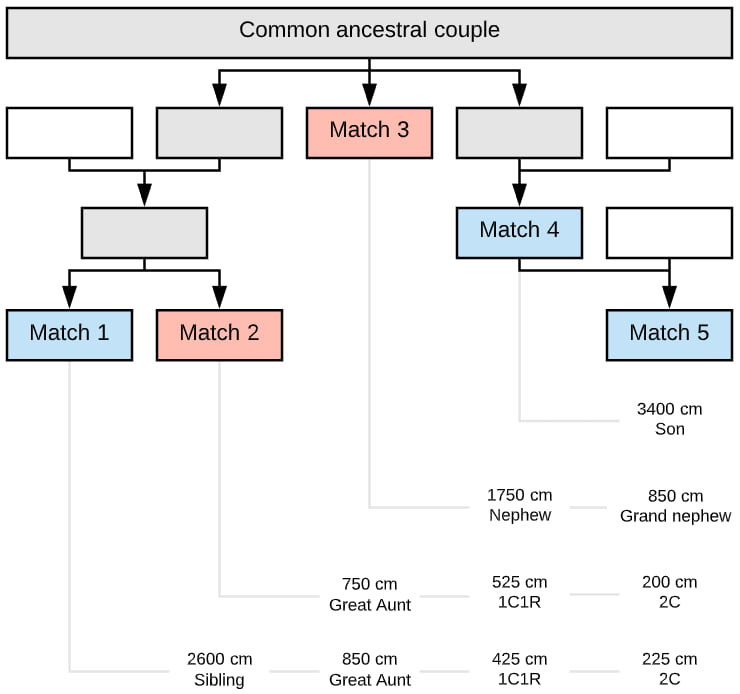
A simple chart like this makes it easier to verify that the tree made from genealogical research matches what’s possible given the amount of shared DNA between any two people in the cluster.
For example, if we find that Match 1 and Match 4 share only 70cm, then it’s very likely our tree is inaccurate. We know that because first cousins once removed typically share about 430cm, with the minimum amount being about 100cm.
If something doesn’t fit, there are many reasons. Most often it’s due to misattributed parentage at some point in the tree.
Genealogists typically use an industry-accepted standard called the Shared Centimorgan Project to suggest relationships based on the amount of shared DNA between any two people.
Not only is this standard used to suggest possible relationships, but it’s also used to eliminate potential relationships.
DNA Painter has a handy tool that uses the data from the Shared Cm Project to show possible relationships and the likelihood for each.
Once all the relationships in a cluster are verified as being viable, the genealogist can move onto the next cluster and repeat the process.
Descendancy research
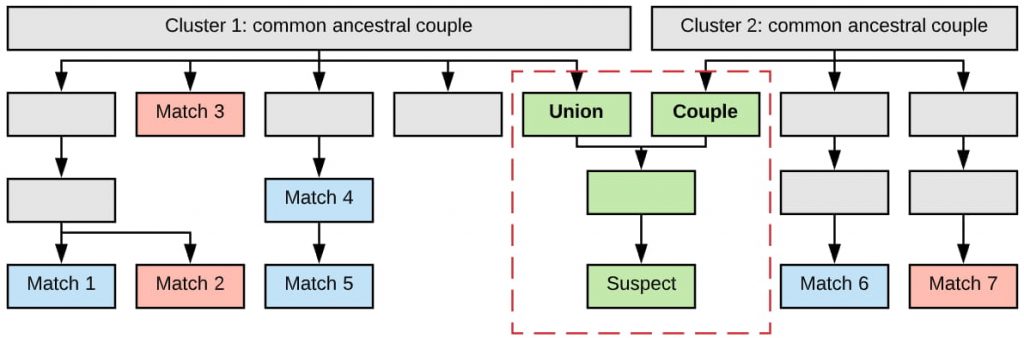
Now comes the tricky part. The genealogist now has two distinct clusters and now must figure out how the clusters connect.
To do that, descendancy research must be done on the common ancestral couple from each cluster.
Now the research comes forward in time to build out the entire family tree of the common ancestral couple’s descendants down to whatever generation was old enough to be the suspect when the crime took place.
The initial descendancy research uses resources like obituaries, old newspapers, census records, public social security databases, people search websites and even social media websites like Facebook.
Because there can be many, many lines to trace, the initial research is done with speed in mind, and the trees created are a bit quick and dirty.
Other, more authoritative sources will be used later to verify the initial research. These might include vital and religious records, will and probate, land records, and many others.
There are also more ways to cut down on the number of lines to trace. For example, if a child of the common ancestral couple married someone who was 100% French and the crime scene DNA estimates 0% French ethnicity, all the descendants from that child can probably be ignored in the beginning.
Likewise, if the crime scene DNA shows a large percentage of German DNA and one of the children married a German, then that line would likely be where the descendancy research begins.
In our example above, all the descendants from the three children of the ancestral couple need to be identified. Additionally, there may be other children of the shared ancestral couple that weren’t uncovered by present-day DNA matches. Those new lines will also need to be explored.
In our example above, the matches in Cluster 1 all stemmed from three children of the common ancestral couple. But genealogical research shows the couple had five children.
The “Union Couple”
When a union is found, those two people will be the suspect’s direct ancestors – possibly the parents, grandparents, great-grandparents, etc.
Next, they continue with the descendancy research, but only on the lines which descend from the union — the suspect’s direct ancestral couple.
Let’s take a simple example and assume that the union couple only had one child, who also only had one child. So now we have two possible candidates: a parent and a child.
If the parent was deceased when the crime was committed, that leaves us with the child as the only possible suspect.
In reality, that initial list of potential suspects is much more extensive. The list comprises all descendants who were alive and of age when the crime was committed. If the suspect’s ancestors are his/her grandparents, the descendant list will likely be small. But if the ancestors are the suspect’s 2x great-grandparents, there will be many more people to consider.
Filtering candidates
This list can be filtered by several variables, such as where each person was living in relation to the crime scene location. For example, if every descendant resided in New York except for one who lived in California where the crime occurred, that person would move to the top of the list.
Each case can have its own set of variables to filter against. If the crime was a sexual assault and the suspect was a male, the female descendants would be filtered out of the list.
Ideally, the list can be filtered down to a few or even a single candidate. It’s often hard to separate siblings of the same gender which is one reason you can end up with several candidates.
Back to law enforcement
This is when the filtered down list of candidates is handed over to law enforcement who will investigate each candidate and, if warranted, lawfully obtain a DNA sample.
I think this part of the investigation tends to be misunderstood, so let me be clear: law enforcement is NOT arresting people based on a genealogist’s research. The genealogist is merely pinpointing the few potential suspects that law enforcement needs to investigate further using traditional methods.
And as we already talked about at the beginning of this article, DNA samples of potential suspects are uploaded to the FBI database, CODIS, to see if it matches the crime scene DNA. Only if there’s an exact match can an arrest be made.
Conclusion
While incredibly effective, you can see how genetic genealogy is merely a way to point law enforcement in the right direction where they still have to use traditional investigative methods. And it’s only when a suspect’s DNA matches the crime scene DNA can an arrest be made.
Believe it or not, this type of genetic genealogy has been around for years and uses the same techniques as adoption cases where an adoptee is looking for their birth parents.
In both scenarios, the goal is to find an unknown person using the matches of the input DNA sample. In criminal investigations, the input is the crime scene DNA. In adoption cases, the input is the adoptee’s DNA.
All charts in this article were made using LucidChart.
WOULD YOU LIKE TO SEE MORE ARTICLES LIKE THIS? SUBSCRIBE TO THE ISHI BLOG BELOW!
SUBSCRIBE NOW!